Le vrai jumeau cognitif n'a pas votre visage
Le jumeau cognitif modélise la structure de pensée d'un individu, pas son apparence. Définition praticienne, méthode des trois flux, démonstration à Dauphine.
Quand on dit « jumeau IA », la plupart des gens pensent deepfake, voix clonée, avatar vidéo. C’est compréhensible - Heygen et ElevenLabs font un travail remarquable sur l’enveloppe visuel et sonore - encore mieux qu’un épisode de Mission : Impossible. Le problème, c’est que reproduire l’apparence de quelqu’un n’a rien à voir avec reproduire sa façon de penser.
Le malentendu : on confond le masque et le cerveau
En octobre 1950, Alan Turing publie « Computing Machinery and Intelligence ». Sa question fondatrice : une machine peut-elle imiter un humain au point de tromper un juge ? Le test de Turing évalue l’apparence du résultat, pas le processus qui l’a produit.
Blade Runner, inspiré de Philip K. Dick, pose la même question trente ans plus tard avec d’autres moyens : le test Voight-Kampff, qui cherche à distinguer l’humain du réplicant par des réponses comportementales. Le critère reste l’imitation convaincante de l’extérieur.
Ces deux cadres - Turing, Blade Runner - ont structuré notre façon d’imaginer l’IA pendant des décennies. Ils posent la bonne question pour les avatars et les deepfakes. Ils posent la mauvaise question pour les jumeaux cognitifs.
Quand Heygen clone une voix et superpose un visage sur une vidéo, le résultat peut être saisissant. Quand ElevenLabs reproduit le timbre vocal d’un dirigeant, la ressemblance est parfois troublante. Ces outils résolvent un problème de forme : rendre l’enveloppe indiscernable.
Ce qu’ils ne font pas : modéliser comment cette personne structure un argument. Quelles heuristiques elle mobilise face à une décision ambiguë. Quel cadre analytique elle applique à un nouveau problème. Avec quel registre elle adapte son discours selon l’interlocuteur.
La bonne question n’est pas « peut-il tromper ? ». Elle est « peut-il penser comme ? ».
Ce qu’est réellement un jumeau cognitif
Un jumeau cognitif repose sur quatre composantes. Elles ne sont pas équivalentes - certaines sont maturées, d’autres relèvent encore du chantier ouvert.
Les schémas de réflexion. C’est le noyau. Comment la personne décompose un problème. Quelles catégories elle mobilise en premier. Quels raccourcis heuristiques elle a internalisés au fil de l’expérience. C’est la partie la plus difficile à formaliser - et la plus déterminante pour que les outputs soient reconnaissables.
Le style de communication. Distinct de la cognition. Un registre écrit soigné ne dit rien sur la façon de raisonner ; il dit comment ce raisonnement est mis en forme. Cette composante se modélise via un artefact concret : un fichier tone of voice qui documente les registres, le rythme, les tournures caractéristiques, les marqueurs lexicaux. Ce n’est pas une notion floue ; c’est un livrable.
La base de connaissances. Deux sous-parties. Les connaissances communes (domaine d’expertise, références théoriques, frameworks analytiques issus d’une formation académique ou par le savoir commun à un moment donné de l’histoire) et les connaissances personnelles (anecdotes, cas vécus, exemples systématiquement cités). Les premières peuvent être importées depuis des sources publiques. Les secondes requièrent une documentation active ou la collaboration de la personne concernée.
Les modèles psychologiques. Ceci reste un chantier non abouti dans l’état de mes réflexions. L’intuition initiale était de s’appuyer sur un modèle formel – le Big Five ou équivalent – pour informer les patterns de décision du jumeau. La recherche académique valide qu’on peut mesurer les traits Big Five dans les outputs LLM (Serapio-García et al., Nature Machine Intelligence, 2025 ↗). Mais les intégrer de façon opérationnelle dans un pipeline de jumeau cognitif reste expérimental. À ce stade, cette composante est une hypothèse de travail, pas une fonctionnalité livrée de mon côté.
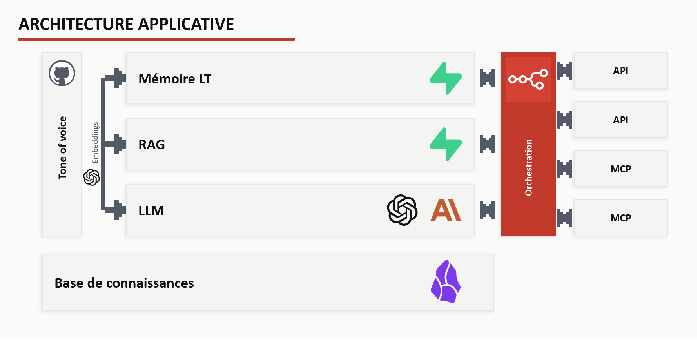
Ce que ces quatre composantes ont en commun : aucune n’est un modèle de langage entraîné from scratch sur les textes de la personne. Un jumeau cognitif, c’est de l’ingénierie de contexte appliquée à un individu. L’intelligence de base vient du LLM généraliste. Le jumeau oriente cette intelligence vers les patterns de l’individu via context engineering, RAG et prompts structurants.
La distinction est importante. Le fine-tuning existe et produit des résultats. Mais il coûte cher, nécessite un corpus conséquent, et ne garantit pas que le modèle « pense comme » la personne – il garantit qu’il produit des outputs statistiquement proches de ses textes. Ce n’est pas la même chose.
La preuve : trois flux pour voir ce que chaque couche apporte
En octobre 2025, j’ai présenté un jumeau cognitif à l’Université Paris-Dauphine. Le sujet : Elon Musk. Le choix est stratégique – pas par fascination pour le personnage, mais pour des raisons méthodologiques. Musk est une figure ultra-documentée : les biographies de Walter Isaacson et d’Ashlee Vance totalisent des milliers de pages. Son style de communication est immédiatement reconnaissable. Son corpus de décisions est abondant et public. C’est le profil idéal pour valider que le jumeau produit quelque chose de discernable.
La méthode de validation repose sur trois flux progressifs. Leur intérêt pédagogique : on voit ce que chaque couche apporte.
Flux 1 - le LLM brut. On pose une question complexe au modèle sans aucune surcouche. La réponse est correcte, informée, bien construite. Et complètement impersonnelle. C’est un LLM qui répond, pas Musk. La baseline.
Flux 2 - le LLM avec RAG. Le modèle a accès à la base de connaissances : extraits des biographies, transcriptions d’interviews, analyses de décisions passées. La réponse gagne en précision. Elle mobilise des références, des exemples, des données que le modèle brut n’aurait pas agrégés aussi efficacement. Mais le style reste celui du modèle - la réponse ressemble à une synthèse documentée, pas à une réponse de Musk.
Flux 3 - le LLM avec RAG et tone of voice. La surcouche complète est active. La réponse est informée et formulée comme Musk l’aurait formulée : les raccourcis heuristiques caractéristiques, le registre oscillant entre technique dense et affirmations tranchées, la tendance à ancrer les arguments dans des analogies physiques ou d’ingénierie. Le public de Dauphine a pu comparer les trois sorties en temps réel.
Un point d’architecture à ne pas passer sous silence : ce n’est pas un prompt magique. Dans l’orchestration, les flux RAG et modèles mentaux sont chargés en amont du contexte (context loading), avec une vérification de cohérence en sortie. C’est un pipeline, pas une formule.
Le critère de réussite ? Le lecteur ne peut plus distinguer l’output du jumeau de ce que la personne aurait écrit.
Ce qui n’est pas encore modélisé
Ce que le pipeline actuel modélise : les schémas de réflexion stabilisés, le style de communication, les connaissances communes et personnelles. Ces composantes produisent des outputs reconnaissables.
Ce qui échappe encore à la modélisation :
L’humeur. L’état émotionnel du moment infléchit les décisions et le registre. Le jumeau produit des outputs cohérents avec le style et les schémas de pensée moyens de la personne - pas avec son état à un instant T. Si Musk rédige une réponse sous pression, ou après une nuit courte, ou dans un contexte de crise, le delta entre le jumeau et la réalité peut être significatif.
La charge mentale. Corrélée à l’humeur, mais distincte : le niveau de fatigue cognitive altère la qualité du raisonnement, pas seulement le ton. Le jumeau produit toujours la meilleure version de la pensée de la personne - ce qui peut, paradoxalement, être un biais.
Le contexte situationnel complet. On peut capturer une partie du contexte via RAG et prompts structurants. Le formaliser exhaustivement et l’embarquer dans le pipeline de façon dynamique reste un défi ouvert.
La formulation la plus honnête : un jumeau cognitif modélise la structure de la pensée, pas l’état du penseur à un moment donné. C’est une photographie du « comment je pense » stabilisé - pas un flux en temps réel du « comment je pense aujourd’hui, dans ces conditions précises ».
Cela n’invalide pas l’approche, à mes yeux. Elle en définit le périmètre d’usage légitime.
Un jumeau cognitif modélise la structure de la pensée, pas l’état du penseur à un moment donné. C’est une photographie du « comment je pense » stabilisé, pas un flux en temps réel.
La recherche académique confirme ces contraintes. Le benchmark How Far are LLMs from Being Our Digital Twins ? (Li et al., ACL 2025) ↗ évalue 1 001 personas sur 15 846 comportements : même les meilleurs LLMs restent en-deçà des humains sur la simulation individuelle. TwinVoice (Du et al., 2025) ↗ mesure que GPT-5 atteint 60 % de fidélité vs 66 % pour les humains cibles (les LLMs sont meilleurs sur le lexique et les opinions, plus faibles sur le ton et la mémoire). Ces benchmarks portent sur des personas génériques. L’approche individuelle praticienne que je défends ici n’est pas encore évaluée dans cette littérature : c’est précisément le vide qu’il s’agit de combler.
Ce que ça change selon votre profil
Pour un consultant ou manager, l’enjeu pratique est celui-ci : un jumeau cognitif bien construit peut répondre à votre place à des sollicitations répétitives qui mobilisent votre cadre d’analyse, sans mobiliser votre attention. Le gain n’est pas la délégation de la décision - c’est la délégation de la formulation quand le cadre est stable.
Pour un profil plus technique, la question qui compte est architecturale : jusqu’où peut-on pousser le context engineering avant que le fine-tuning devienne plus efficace ? Mon expérience sur le cas Musk suggère que le context engineering couvre 80% du chemin pour les profils ultra-documentés. Pour des individus moins publics, avec un corpus plus mince, la réponse change.
Pour un étudiant ou curieux : si vous voulez expérimenter, commencez par le tone of voice. Documentez votre style d’écriture - vos tournures, vos registres, vos marqueurs lexicaux - dans un fichier structuré. Appliquez-le à un LLM sur quelques productions. La distance entre le résultat et votre voix naturelle vous dira exactement ce qu’il manque encore.
Avant de partir
Un jumeau cognitif n’est pas une technologie - c’est une discipline d’ingénierie de contexte. Son niveau de fidélité dépend directement de la rigueur avec laquelle on a documenté la pensée de la personne avant de la modéliser.
Le terme « clone IA » est doublement inexact : il suggère une duplication fidèle (impossible, pour les raisons d’état et de charge mentale évoquées plus haut) et une fabrication à partir de rien (faux - le LLM généraliste fait le gros du travail cognitif). Le jumeau cognitif oriente une intelligence existante. Il ne la remplace pas.
La méthode des trois flux reste, à ma connaissance, la façon la plus lisible d’expliquer ce que chaque couche apporte.
Il reste beaucoup à documenter sur les modèles psychologiques, la charge mentale, et l’évaluation des cas non-publics. Ce n’est pas un manque – c’est la prochaine étape.
Les opinions exprimées ici sont personnelles et n'engagent pas mon employeur.