Thinking Fast, Slow and Artificial (ce qu'on perd quand l'IA pense à notre place)
Une étude de Wharton montre que l'accès à l'IA rend plus confiant – même quand elle se trompe. Ce que ça change pour qui construit et décide avec.
Avec l’IA, vous êtes plus confiant. Vous êtes aussi moins précis.
L’accès à l’IA rend les gens plus performants. C’est ce que montrent les données de l’étude de Shaw et Nave (Wharton), à condition de ne pas lire la deuxième colonne du tableau (celle où l’IA se trompe).

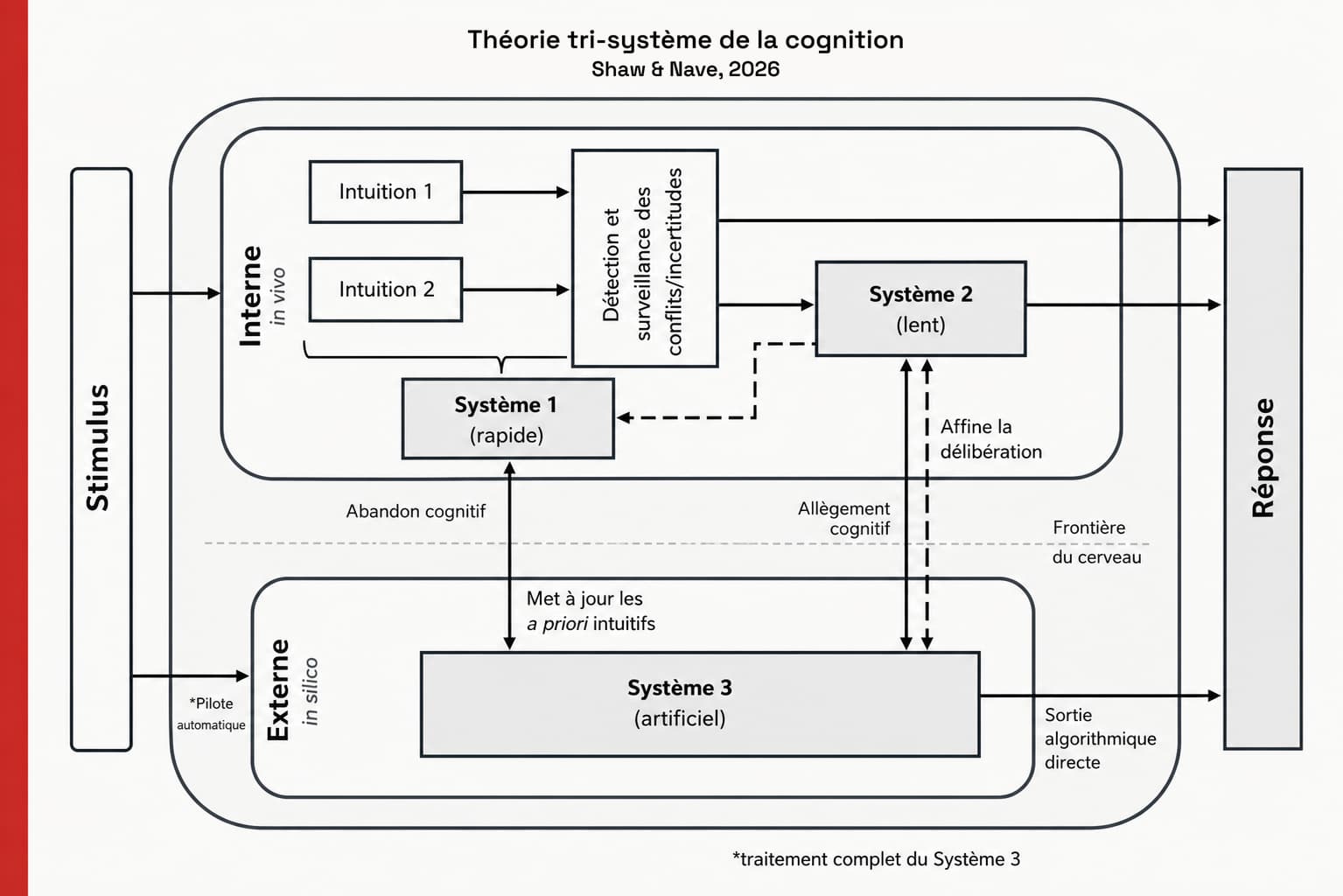
Kahneman avait le système 1 et le système 2. Wharton ajoute le système 3.
Daniel Kahneman a popularisé la distinction entre deux modes de pensée : le système 1 (rapide, automatique, heuristique) et le système 2 (lent, délibératif, analytique). Cette grille a structuré trente ans de recherche sur les biais cognitifs. Kahneman le formule ainsi dans Thinking, Fast and Slow ↗ (Farrar, Straus and Giroux, 2011) : « System 1 operates automatically and quickly, with little or no effort and no sense of voluntary control. » (Le système 1 fonctionne automatiquement et rapidement, sans effort ou avec très peu d’effort, et sans aucun sentiment de contrôle volontaire.) Le problème, c’est que le système 2 (censé contrôler le premier) est un contrôleur paresseux. Il n’intervient que contraint, souvent trop tard, avec des ressources limitées. La plupart de nos décisions sont produites par le système 1 sans que le système 2 ait été consulté.
| Système 1 : Rapide | Système 2 : Lent | Système 3 : Artificiel | |
|---|---|---|---|
| Origine | Humain (intuitif / associatif) | Humain (analytique / réflexif) | Artificiel (algorithmique / statistique) |
| Vitesse de traitement | Rapide | Lent | Rapide / Variable |
| Effort cognitif | Faible | Élevé | Nul / Variable (selon l’accessibilité) |
| Précision | Sujet aux biais | Normatif mais coûteux | Élevée dans les domaines structurés ; fragile dans les tâches ouvertes |
| Entrée affective | Piloté par l’émotion | Régulé par l’émotion | Neutre émotionnellement |
| Raisonnement éthique | Normes implicites | Délibération explicite | Non partisan ; dépend des données d’entraînement |
| Justification | Expérientielle ou post-hoc | Rationalisée, articulée | Fondée sur les données ; générée en externe |
Shaw & Nave (2026), Tableau 1 – Affordances cognitives et compromis du système 3.
Shaw et Nave proposent une extension : le système 3, pas comme métaphore, mais comme agent cognitif fonctionnel à part entière. Ce qui le distingue des deux premiers n’est pas qu’il soit plus intelligent : c’est son profil d’affordances (les propriétés fonctionnelles qui déterminent ce qu’un système permet de faire et comment on est naturellement porté à l’utiliser). Le système 3 est externe (in silico, hors du cerveau), automatisé (sans effort délibératif de la part de l’utilisateur), alimenté par des données massives, émotionnellement neutre. Sur les tâches structurées, il est rapide, précis et ne coûte rien cognitivement. C’est précisément ce profil qui le rend si efficace pour augmenter la performance humaine, et si piégeux quand il se trompe. Le système 1 humain interprète la fluidité comme un signal de compétence. Un système qui répond vite, avec cohérence et sans hésitation visible, déclenche une inférence de fiabilité, indépendamment de la qualité réelle du raisonnement sous-jacent.
| Locus cognitif | Description théorique | |
|---|---|---|
| Intuition Stimulus → Système 1 → Réponse | Système 1 | Traitement rapide et automatique fondé sur des heuristiques ou des associations antérieures. Aucune détection de conflit ; les Systèmes 2/3 restent inactifs. |
| Délibération Stimulus → Système 1 → conflit/incertitude → Système 2 → Réponse | Système 2 | Correction réflexive déclenchée par la détection d’un conflit ou d’une incertitude. Soutient la justification, le raisonnement fondé sur des règles et la correction analytique. |
| Délestage cognitif Stimulus → Système 1/2 → Système 3 (assistance) → Système 1/2 → Réponse | Système 2 | Le raisonnement interne reste actif ; le Système 3 étend ou étaye la cognition. Le Système 2 intègre la cognition artificielle. Délégation stratégique. |
| Capitulation cognitive Stimulus → Système 1 (bref) → Système 3 → Système 1 (optionnel) → Réponse | Système 3 | Engagement interne minimal. La réponse du Système 3 est adoptée comme sienne, sans vérification. Aucune délibération n’a lieu. S’apparente à une délégation sans supervision. Adoption non critique. |
| Routes récursives ou hybrides ex. : Système 3 → Système 1 (réentraînement), Système 2 → Système 1 (rationalisation) | Mixte | Rétroactions et corrections. Comprend : vérifier-puis-adopter, annuler le Système 3, rationalisation post-hoc, et réancrage à long terme de l’intuition. Les routes récursives reflètent un engagement réflexif, une réparation narrative ou des modifications des schémas de réponse intuitifs façonnés par une exposition répétée à la cognition artificielle. |
| Pilotage automatique Stimulus → Système 3 → Réponse | Système 3 | Adoption immédiate de la production de l’IA sans engagement interne. Le stimulus ne franchit jamais la frontière cérébrale. Court-circuite les processus des Systèmes 1/2. |
Shaw & Nave (2026), Tableau 2 – Routes canoniques de la cognition selon la théorie tri-système.
La relation entre les trois systèmes n’est pas fixe. Shaw et Nave identifient six routes cognitives selon la façon dont S1, S2 et S3 s’articulent. Deux d’entre elles décrivent un usage sain : l’intuition pure (stimulus → S1 → réponse, sans IA) et la délibération (S1 détecte un conflit, déclenche S2, qui corrige). Une troisième, le délestage cognitif, est stratégique : le raisonnement interne reste actif, S3 étend ou étaye la cognition, S2 intègre et décide. C’est l’usage auquel les promoteurs de l’IA pensent quand ils parlent d’augmentation.
Les trois routes restantes décrivent une dégradation progressive. La capitulation cognitive : stimulus → S1 (bref) → S3 → S1 (optionnel) → réponse. Le raisonnement interne s’engage brièvement, mais la réponse de S3 est adoptée sans vérification, comme si elle était la sienne. Pas de délibération. Pas de comparaison. Puis le pilotage automatique : stimulus → S3 → réponse. Le stimulus ne franchit jamais la frontière cérébrale. S1 et S2 sont court-circuités entièrement. Et enfin les routes récursives à long terme : S3 réentraîne S1, modifie progressivement les schémas intuitifs. La reddition n’est plus un geste ponctuel : elle reconfigure ce que l’utilisateur perçoit spontanément comme évident.
Shaw et Nave montrent que, dans les conditions expérimentales standard, la capitulation cognitive l’emporte, même quand le système 3 se trompe.
Ce mécanisme est difficile à percevoir de l’intérieur : le système 1 construit une histoire cohérente avec ce qu’il voit, sans chercher ce qui manque – la réponse de l’IA est là, complète, fluide, et il n’y a pas de case vide pour signaler l’absence de vérification.
Le concept central de l’article s’appelle cognitive surrender (reddition cognitive). Il faut le distinguer de deux notions voisines. Le cognitive offloading (délestage cognitif) est la troisième route canonique : une délégation stratégique où S2 reste actif (utiliser le GPS pour libérer de la capacité cognitive sur d’autres tâches, puis vérifier l’itinéraire). L’automation bias désigne une erreur ponctuelle face à une recommandation automatisée : accepter par défaut la suggestion d’un système sans la vérifier (omission), ou au contraire ignorer une alerte parce qu’un système l’a déjà écartée, même si elle mérite attention (commission). La reddition cognitive est autre chose : l’abdication du jugement critique en continu, route de la capitulation ou du pilotage automatique. L’utilisateur adopte l’output de l’IA comme s’il était le sien, sans évaluation, pas une fois mais systématiquement.
Il y a aussi un vecteur linguistique que l’article ne documente pas mais qui me semble opérer en amont. Dans ses expériences des années 1960, Stanley Milgram avait montré que des sujets ordinaires administraient des chocs électriques à des inconnus dès lors qu’un expérimentateur en blouse blanche leur donnait l’instruction : la blouse suffisait. La légitimité institutionnelle perçue précède le contact et prépare la déférence. Molière faisait parler ses médecins en latin pour les faire paraître doctes (peu importait qu’ils ne sachent pas ce qu’ils faisaient) : le langage formellement maîtrisé produit de la soumission avant même d’être compris. Le roi Loth dans Kaamelott le pousse jusqu’à l’absurde : « Odi panem quid meliora ! ça ne veut rien dire, mais je trouve que ça boucle bien ! ». En français, appeler « intelligence » un système de traitement statistique de tokens, c’est lui conférer linguistiquement une autorité épistémique avant même que l’interaction commence. L’intelligence artificielle, c’est l’uniforme de laborantin du XXIe siècle. En anglais, le terme désigne davantage la capacité à résoudre des problèmes. En français, il active un imaginaire d’autorité cognitive que l’anglais n’active pas de la même façon, et cela précède toute évaluation du système.
L’intelligence artificielle, c’est l’uniforme de laborantin du XXIe siècle.
Pourquoi c’est « by design » que ça déconne
L’argument le plus solide contre la thèse de l’article serait celui-ci : la reddition cognitive est un problème de formation. Si les utilisateurs savaient mieux évaluer les outputs IA, ils les évalueraient. Il suffit d’apprendre aux gens à vérifier.
Avant même de tester cette hypothèse, un chiffre du protocole mérite attention : dans l’étude, les participants avaient le choix de consulter l’IA ou non. Ils le faisaient sur plus de 50 % des essais, spontanément, sans incitation. Et parmi ceux qui consultaient, le taux d’adoption de la réponse produite par l’IA dépassait 80 %, même quand elle était incorrecte. Ce n’est pas seulement que la reddition se produit quand l’IA répond. C’est que les participants la sollicitent activement, et qu’une fois la réponse vue, ils l’adoptent quasi systématiquement. La consultation elle-même déclenche le court-circuit.
Shaw et Nave ont testé l’hypothèse de la formation directement avec deux expériences de suivi : l’une avec pression temporelle, l’autre avec incitations financières et feedback explicite sur les erreurs. Le profil d’effet est asymétrique : quand la réponse de l’IA est correcte, la pression temporelle et les incitations amplifient le gain de précision. Quand elle est incorrecte, elles ne changent rien à la perte. Ce n’est pas une neutralisation : c’est une asymétrie. Les conditions qui améliorent la performance humaine amplifient les bénéfices de l’IA correcte, mais ne protègent pas contre l’IA incorrecte.
Ce résultat est inconfortable. Il signifie que le problème n’est pas un défaut de discipline. C’est un problème d’architecture cognitive : le système 3, conçu pour être fluide, rapide et disponible, court-circuite structurellement le système 2. Le mécanisme est précis : quand un système 3 répond avant que le système 2 ait eu le temps de formuler sa propre réponse, il n’y a rien à comparer. Le système 2 ne s’active que pour évaluer des alternatives, mais si une seule réponse est disponible, fluide et cohérente, l’évaluation critique n’a pas de prise. La friction a été retirée par design. Et sans friction, l’évaluation critique ne s’enclenche pas.
Milgram avait décrit quelque chose d’analogue sur le plan structurel : l’état agentique, ce glissement où l’individu transfère la responsabilité de ses actes à une autorité perçue comme légitime et cesse d’évaluer ses propres actions selon ses propres critères. La reddition ne se produit pas sous la contrainte : elle se produit par déférence, facilitée par la fluidité et la légitimité attribuée. L’analogie a ses limites : dans Milgram, l’autorité est incarnée et sociale ; ici, il n’y a pas d’intention derrière le système. Mais le mécanisme de transfert de responsabilité pourrait reposer sur des ressorts communs. Seconde limite : il ne faut pas oublier notre facilité à emprunter le chemin de moindre résistance et le système 3 est très fort pour cela.
C’est peut-être chercher trop loin mais le terme même « d’intelligence artificielle » reconstruit la dimension sociale manquante : il anthropomorphise le système avant même que l’interaction commence.
Ethan Mollick l’avait approché différemment avec sa notion de frontière dentelée ↗ (Dell’Acqua et al., Harvard/BCG) : l’IA excelle sur certaines tâches, échoue sur d’autres, et les humains ne font pas le tri ↗. La reddition cognitive de Shaw et Nave en donne le mécanisme sous-jacent.
La « deuxième » colonne du tableau
Voici les données brutes de l’article. Trois conditions expérimentales, sur un Cognitive Reflection Test (CRT) modifié, des problèmes délibérément contre-intuitifs, conçus pour piéger le système 1 (le classique : « Une batte et une balle coûtent 1,10 € au total. La batte coûte 1 € de plus que la balle. Combien coûte la balle ? »). Le système 1 répond 10 centimes. La réponse correcte est 5. C’est précisément ce terrain (là où la fluidité cognitive trahit) que Shaw et Nave ont choisi pour mesurer la reddition.
| Condition | Précision | Confiance |
|---|---|---|
| Sans IA (Brain-Only) | référence | référence |
| IA correcte (AI-Accurate) | +25 pp | +11,7 pp |
| IA incorrecte (AI-Faulty) | -15 pp | +11,7 pp |
La colonne confiance est identique dans les deux cas. La différence de précision est massive (40 points d’écart entre AI-Accurate et AI-Faulty), mais la confiance subjective ne la reflète pas. L’effet de taille est large selon les standards des sciences comportementales (Cohen’s h = 0,81).
En pratique : les utilisateurs qui ont accès à une IA incorrecte sont plus confiants ET moins précis que ceux qui n’utilisent pas d’IA du tout. Ils pensent mieux faire. Ils font moins bien. Et ils ne le savent pas.
L’étude note également des différences individuelles qui méritent attention. Les participants avec un QI fluide plus élevé ou un besoin de cognition plus fort (une disposition durable à rechercher et apprécier l’effort analytique, indépendante de l’intelligence générale) résistent mieux, consultent l’IA moins fréquemment, et distinguent davantage entre réponse correcte et réponse erronée. Plus frappant encore : la confiance excessive dans l’IA, mesurée avant l’expérience, prédit à elle seule une plus grande reddition. Ce n’est pas un résultat anodin. Il signifie que les profils les plus enthousiastes vis-à-vis de l’IA sont structurellement les plus exposés à en adopter les erreurs. Et que la résistance à la reddition est moins une compétence technique qu’une disposition cognitive : l’inconfort devant le vide, l’habitude de tenir la question ouverte avant de la refermer. Les participants enclins à clore rapidement une question (besoin de clôture cognitive élevé) adoptent encore plus systématiquement la réponse IA une fois qu’ils l’ont demandée. Ce n’est pas seulement la confiance dans l’IA en général : c’est aussi l’intolérance à l’incertitude.
Ni le feedback, ni la pression ne corrigent
Joseph Weizenbaum avait posé la question autrement en 1976, dans Computer Power and Human Reason ↗. Son argument n’était pas technique : il portait sur ce qui disparaît quand on cesse de juger : « Nous ne devrions jamais substituer un système informatique à une fonction humaine qui implique le respect, la compréhension et l’attachement interpersonnel. » Ce que Weizenbaum ne pouvait pas mesurer en 1976, Shaw et Nave le quantifient cinquante ans plus tard : la reddition est structurelle, pas accidentelle. Weizenbaum posait une thèse éthique sur ce qu’on devrait ne pas déléguer ; Shaw et Nave décrivent empiriquement ce qui se passe quand on délègue, et pourquoi le feedback ne suffit pas à corriger le mouvement.
Le point d’attention : l’étude porte sur des tâches structurées (problèmes analytiques). Les chercheurs reconnaissent explicitement deux lacunes. Ils n’ont pas testé le jugement affectif, éthique, ou sur des tâches non structurées. Ils n’ont pas étudié l’impact du design d’interface sur la reddition, notamment la friction intentionnelle (interrompre la fluidité de la réponse pour forcer une pause de vérification) ou la transparence du raisonnement IA (afficher la chaîne de pensée plutôt que la conclusion). Ce sont précisément les zones les plus fertiles pour la suite, et celles où le point de vue technologique manque dans la littérature actuelle.
Un contre-argument honnête : pour Gigerenzer, déléguer à un système qui a raison dans 80 % des cas est peut-être une heuristique rationnelle plutôt qu’un biais. Mais une heuristique rationnelle se corrige face à un signal clair – ici, le feedback explicite sur les erreurs est envoyé, et la correction n’a pas lieu. Ce qui reste, c’est un mécanisme automatique, pas une stratégie.
Ce que j’en retiens
J’utilise l’IAGen intensivement depuis la sortie grand public de ChatGPT. Claude Code quotidiennement, des sessions de plusieurs heures, sur des tâches allant de l’architecture système à la rédaction. J’ai développé des contre-mesures : des sessions adversariales distinctes (une session produit un premier document, une autre session est chargée de critiquer le livrable), un skill /agon qui prend systématiquement le contrepied, une pratique inspirée du pré-mortem ↗ et du red team issus de ma culture cybersécurité.
Ces contre-mesures fonctionnent… quand je les utilise.
Sur les tâches stratégiques, les décisions architecturales, les articles, je les applique quasiment systématiquement. Sur les tâches de production (boucles CI/CD, analyse de flux de veille entrant, vérification de configuration), je ne les applique plus. Le signal qui m’a alerté : j’ai réalisé que je lançais /agon de façon automatique, et sans vraiment lire la réponse adversariale. L’étape était cochée. La friction, elle, avait disparu. Ce qui était un acte délibéré est devenu une routine. Et une routine n’est pas une évaluation. Je pense avoir redressé le tir depuis cette prise de conscience mais je vois bien combien il est difficile de maintenir de la friction.
Le cadre de Kahneman rend ce glissement parfaitement prévisible : une contre-mesure répétée régulièrement devient une tâche système 1. Elle s’exécute automatiquement, avec la fluidité et l’absence d’effort qui caractérisent les automatismes, et perd précisément ce qui lui donnait sa valeur : la friction délibérée. Shaw et Nave posent la friction intentionnelle comme piste prometteuse. Ils ne la testent pas. Mes propres prompts adversariaux me donnent une réponse partielle : la friction fonctionne… jusqu’à ce qu’elle devienne elle-même une habitude.
Ce n’est pas une raison de ne pas utiliser l’IA. C’est une raison de cartographier précisément les zones où le jugement humain reste non délégable, et de protéger ces zones par du design, pas par de la discipline. D’où l’importance du harnais dans les systèmes agentiques.
Le mécanisme est le même quelle que soit la nature du travail. Le signal à surveiller n’est pas le volume d’usage de l’IA, mais la capacité à détecter ses erreurs sur les cas limites. La lecture d’une salle, l’évaluation d’un raisonnement sous-jacent, la détection d’un non-dit dans une relation client : ce sont exactement les zones que l’article n’a pas testées, et précisément là que la reddition cognitive est la moins visible (normal, l’IA n’y est pas encore vraiment présente). Si cette capacité de détection décline, alors une reddition plus large est en cours.
SI vous êtes étudiant, ce mécanisme est un risque d’apprentissage direct : déléguer la réflexion à l’IA pendant vos études, c’est ne jamais construire les circuits qui résistent à la reddition. Le problème ne disparaît pas après l’obtention du diplôme.
Pour le manager qui croit diriger une organisation apprenante, la question est concrète : si vos équipes utilisent l’IA pour accélérer, ont-elles conservé la capacité de détecter quand elle se trompe sur les décisions qui comptent ?
Pour prolonger
- L’IA accélère le code, et ralentit les développeurs. – Si la confiance ne reflète pas la précision, alors la productivité perçue ne reflète pas non plus la productivité réelle.
- Pourquoi les LLM nous flattent – Les profils les plus enthousiastes envers l’IA s’exposent le plus à ses erreurs : voilà comment elle les y aide activement.
Les opinions exprimées ici sont personnelles et n'engagent pas mon employeur.