La veille IA nourrit la reconnaissance, votre pratique construit votre compétence
Comment progresser sur le prompting IA sans se noyer dans les newsletters – sources sélectionnées, rituels efficaces, et ce que la recherche dit sur ce qui fonctionne.
Vous avez souscrit aux newsletters du Journal du Net, à Ethan Mollick ↗ et trois autres infolettres spécialisées sur l’IA. Chaque mardi, vous lisez en diagonal. Chaque jeudi, vous oubliez. Dans six mois, vous avez suivi l’actualité sans jamais changer une ligne de votre manière de travailler avec un LLM.
Le vrai problème n’est pas le volume d’information
J’ai passé plusieurs semaines à accumuler newsletters et vidéos YouTube sur le prompting. Taux de lecture réel ? A peine au-dessus de zéro. Les vidéos, c’est plus vicieux encore : le contenu paraît brillant, l’intention d’appliquer est sincère, l’effet sur la pratique quotidienne est quasi nul. Assister à une démonstration nous donne l’illusion de savoir, or il y a un monde entre comprendre et savoir.
L’algorithme YouTube y est pour quelque chose. Il surexpose la nouveauté et récompense la fraîcheur plutôt que la profondeur. Résultat : des dizaines de chaînes se copient sur les mêmes sujets (les vidéos sur l’automatisation de leads LinkedIn avec l’IA ont dû dépasser le millier). Le vrai problème n’est pas de trouver du contenu. C’est de trouver le « patient 0 » (celui qui a produit l’idée originale avant que ses voisins la recyclent), sinon de trouver le « copieur » qui vous plaît.
Neil Postman décrivait déjà ce mécanisme dans Technopoly (1992) : le problème de la société de l’information n’est pas la pénurie d’information, c’est la destruction des filtres qui permettaient de lui donner du sens. Nous n’avons pas besoin de plus de sources IA. Nous avons besoin de meilleurs critères de tri.
La veille a aussi un biais neurologique. Sébastien Bohler, dans Le Bug humain (2019), documente comment le striatum - circuit de récompense dopaminergique - est activé par la nouveauté informationnelle. Ouvrir 25 onglets en se disant « je lirai plus tard » n’est pas de la curiosité : c’est du FOMO (Fear of missing out, la peur de rater quelque chose d’important). La satisfaction est immédiate ; la compétence, elle, ne vient pas.
Ce que la recherche dit réellement sur les techniques de prompting
La littérature académique sur le sujet grossit rapidement. Deux résultats méritent d’être retenus parce qu’ils vont à l’encontre du sens commun.
Sur-prompter dégrade les performances. Tang, Tuncel, Koerner et Runkler (arXiv, sept. 2025) ↗ ont documenté ce qu’ils appellent le « Few-shot Dilemma » : au-delà d’un certain nombre d’exemples dans un prompt, les performances des modèles diminuent. Ce résultat a une implication souvent passée sous silence : le few-shot prompting, technique enseignée dès les premiers temps du prompt engineering comme une bonne pratique universelle et qui consiste à donner plusieurs exemples au LLM avec son prompt, fonctionne différemment selon la génération de modèle. Sur les modèles antérieurs à GPT-3.5, donner des exemples permettait effectivement de cadrer la réponse. Sur les modèles dits « thinking », qui raisonnent avant de répondre, des exemples trop prescriptifs contraignent le modèle dans le mauvais sens - ils limitent l’espace de raisonnement plutôt que de le guider. Le few-shot reste utile, mais en fin de séquence, une fois que des prompts plus ouverts ont permis au modèle d’exprimer sa pleine capacité. En apprenant une astuce sans comprendre pourquoi elle fonctionne, on hérite d’un réflexe qui se périme en même temps que la génération de modèle qui lui donnait du sens.
En apprenant une astuce sans comprendre pourquoi elle fonctionne, on hérite d'un réflexe qui se périme en même temps que la génération de modèle qui lui donnait du sens.
Le zero-shot bien formulé tient face aux approches complexes. Kojima et al. (NeurIPS, 2022) ↗ ont montré que les grands modèles sont de bons raisonneurs zero-shot (sans exemple dans le prompt) à condition d’activer explicitement leur capacité de raisonnement (soit en activant directement l’option du modèle “réflexion avancée”, soit avec une phrase déclencheuse - “think hard”). Le point d’entrée accessible est souvent suffisant.
Ce que l’étude de Schulhoff et al. (arXiv, 2024-2025) ↗ synthétise sur 58 techniques de prompting référencées confirme la même logique : la maîtrise ne tient pas au nombre de techniques connues, mais à la compréhension des mécanismes qui font qu’une technique fonctionne. Schulhoff en parle en détail dans son entretien chez Lenny’s Podcast (2025) ↗ : ce qui a changé fondamentalement depuis 2022, c’est moins l’outillage que la compréhension des modèles eux-mêmes.
Un troisième résultat mérite d’être signalé : l’ingénierie de prompt (prompt engineering) s’est transformée en quelque chose de plus large qu’Addy Osmani appelle context engineering ↗ (ingénierie du contexte). Il ne s’agit plus seulement de formuler une instruction, mais de structurer l’ensemble de l’information que le modèle reçoit : mémoire, outils disponibles, exemples, instructions système ; appliqué à un individu, cela donne un jumeau cognitif. Il faut ajouter à cela une tendance de fond chez les fournisseurs de modèles : améliorer de mois en mois les interfaces pour que la « discussion simple » donne de meilleurs résultats sans technique. L’accessibilité est un enjeu commercial. Dans mon observation, les techniques qui compensaient des lacunes d’interface tendent à disparaître à mesure que l’interface s’améliore.
Pourquoi les astuces isolées ne construisent pas de compétence
C’est ici que le philosophe Michael Polanyi éclaire quelque chose que les guides de prompting ne disent jamais. Dans The Tacit Dimension (1966), il écrit : « We can know more than we can tell. » La connaissance tacite, celle qui guide un expert, peut résister à la formalisation. On ne peut pas la transmettre par une liste de règles.
La compétence en prompting ressemble à ça. Savoir quand utiliser une chaîne de vérification (chain-of-verification) plutôt qu’un prompt direct, comment adapter le niveau de détail selon le modèle utilisé, pourquoi une instruction trop longue peut nuire autant qu’une instruction trop courte : ces jugements s’acquièrent par la pratique répétée, pas par la lecture de guides, aussi bien documentés soient-ils.
C’est la distinction qui compte : la veille nourrit la reconnaissance (savoir que X existe). La pratique construit la compétence (savoir utiliser X). La veille sans pratique produit des gens qui connaissent beaucoup de techniques sans en maîtriser aucune (un paradoxe bien documenté sur la productivité réelle avec l’IA).
La question pertinente pour un manager n'est pas « mon équipe connaît-elle les techniques de prompting ? » mais « mon équipe teste-t-elle régulièrement des choses pertinentes ? »
L’argument inverse existe, et il mérite d’être énoncé clairement : comprendre les principes sans s’exposer à des exemples concrets ne construit pas non plus de compétence. Ce que je défends ici n’est pas « lisez moins, pratiquez plus » comme mantra creux, mais une séquence : comprendre les logiques de fond, repérer les techniques adaptées à ses cas d’usage réels, les tester immédiatement. Les deux plans – compréhension et pratique – fonctionnent en aller-retour permanent, pas en séquence linéaire. La veille n’a de valeur que si elle débouche sur une expérimentation dans les jours qui suivent.
La progression : comprendre les logiques, puis choisir ses techniques
Comprendre les grandes logiques des modèles d’abord.
Avant de chercher des astuces de prompting, il est utile de comprendre comment les modèles de langage fonctionnent et, surtout, comment ils échouent. Quelques mécanismes changent durablement la façon de construire un prompt :
- Les modèles sont entraînés à plaire. C’est ce que j’appelle la flagornerie computationnelle : un prompt qui cherche une validation obtient souvent une validation.
- La gestion du contexte a des limites réelles : au-delà d’une certaine proportion de la fenêtre de contexte (la taille maximale de contenu que le LLM peut traiter en même temps), les informations au milieu sont moins bien traitées que celles en début et en fin (actuellement, la baisse de compréhension se trouve à la milieu de la fenêtre de contexte).
- Les modèles dits « thinking » (qui raisonnent avant de répondre) se comportent différemment des modèles classiques sur les tâches complexes – le few-shot prompting, en particulier, s’y utilise autrement.
- Les outils disponibles (MCP, function calling (appel de fonction), les skills) changent la nature de l’interaction : le prompt n’est plus une instruction isolée, mais une pièce d’un système.
Pour ce premier niveau, le guide officiel OpenAI pour GPT-5 ↗ est une bonne référence de départ, applicable aux autres modèles. Le cours OpenAI Academy sur le prompt engineering (2025) ↗ ou d’Anthropic ↗ couvrent bien plus que les bases - et de façon structurée. C’est ma recommandation principale en avril 2026.
Puis identifier les familles de techniques utiles à ses cas d’usage.
Une fois les logiques de fond comprises, la question est : quelles techniques servent mes usages réels ? Pas une taxonomie exhaustive des 58 techniques recensées par Schulhoff, mais 5 à 8 patterns qui reviennent dans son travail quotidien. Pour la beauté du geste, j’ai crash-testé l’essentiel des 58 techniques adaptables à mes usages (hors calculs et recherches scientifiques), en évaluant la qualité des résultats avant/après… Je vous épargne les résultats (devenus partiellement obsolètes).

Le Prompting Guide ↗ offre une référence structurée pour explorer ces familles. Le zero-shot, le few-shot (avec parcimonie et en fin de séquence comme évoqué plus haut), la chaîne de pensée (chain-of-thought, soit enchaîner des questions de raisonnement intermédiaires), le recadrage du rôle assigné au modèle : ces patterns couvrent 80 % des cas d’usage pratiques. A la chaîne de pensée, je préfère la chaîne de vérification (chain-of-verification) - exemple en fin de page - parce que la question des sources est bien plus importante que d’imposer un mode de réflexion à un modèle thinking.
Comment organiser une veille qui ne consomme pas tout votre temps disponible
La veille sur le prompting suit la même logique que la veille sur n’importe quel domaine technique en évolution rapide : l’enjeu est de distinguer ce qui change fondamentalement de ce qui est du marketing éditorial autour d’un sujet porteur.
Quelques sources qui tiennent sur la durée, parce qu’elles produisent du contenu original plutôt que de recycler :
- Ethan Mollick – One Useful Thing ↗ : analyse pragmatique de l’usage de l’IA dans le travail du savoir. Mollick est chercheur à Wharton et praticien ; il documente des effets mesurés plutôt que des impressions.
- Ben’s Bites ↗ : sélection quotidienne de l’actualité IA pour les praticiens. Dense, sans rhétorique.
- Yannic Kilcher (YouTube) ↗ : analyse de publications scientifiques récentes. Crédibilité technique sans basculer dans la recherche pure. Utile pour comprendre les évolutions de fond plutôt que les annonces de produits.
- Cameron R. Wolfe, Advanced Prompt Engineering (Substack, 2025) ↗ : pour aller plus loin sur les mécanismes.
Sur la fréquence : mieux vaut lire une newsletter par semaine avec attention qu’en recevoir cinq qu’on scanne en diagonal. Le critère de sélection est simple : préférer la source dont vous pouvez identifier l’auteur original, et méfiez-vous de celle qui a quelque chose à vous vendre. J’aime bien ce que fait Benoît Raphaël ↗, c’est souvent incarné avec des anecdotes personnelles. Certes il fait la promotion de ses services, mais il ne vend pas son âme à cette fin. Parmi les chaînes YouTube que je vous recommande, il y a celle de Mark Kashef ↗. Il est très centré Claude (moi aussi…), et s’il y a une évolution « majeure » dans le domaine, il l’aura traitée en moins d’une semaine. C’est un laps de temps bien trop important si vous vivez dans Geekland, mais si vous vivez dans Normalland, c’est une approche optimale.

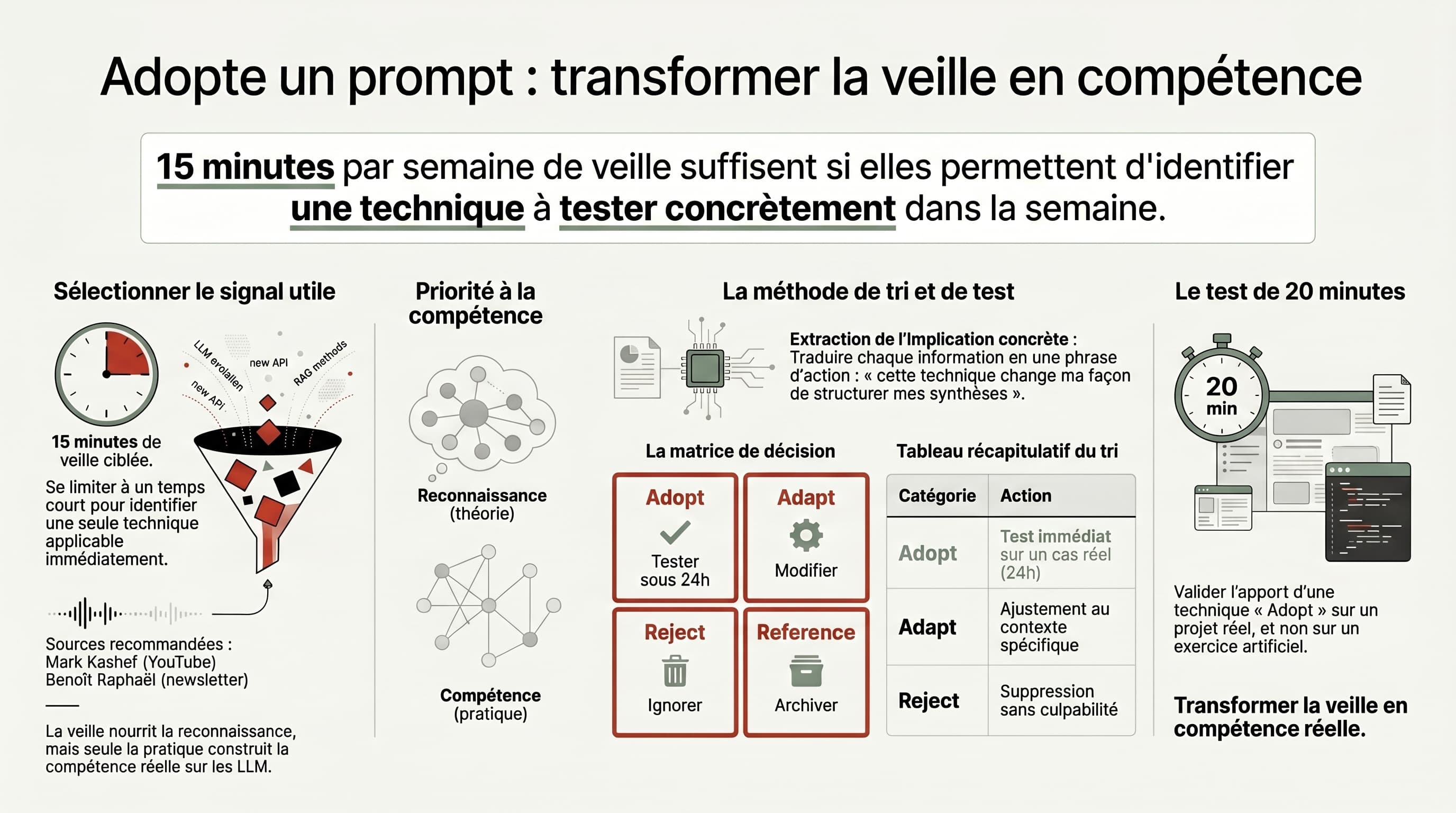
Du signal à la pratique : « Adopte un prompt »
La veille utile n’est pas celle qui couvre le plus de terrain. C’est celle qui débouche sur un test dans les 48 heures.
Un protocole qui fonctionne, à adapter selon votre usage :
- Tri à la source : parcourir vos 1-2 sources sélectionnées. Pour chaque contenu, une seule question – « est-ce que ça change quelque chose à ma pratique actuelle ? ». Si non : zapper, sans culpabilité. Si oui : passer à l’étape suivante.
- Extraction de l’apport : noter en une phrase ce que ça apporte – pas un résumé, une implication concrète. « Cette technique change la façon dont je structure mes demandes de synthèse » vaut mieux que « article intéressant sur le prompting ».
- Classement rapide : Adopt (tester dans les 24h) / Adapt (à tester mais à modifier pour mon contexte) / Reject (pas pertinent maintenant) / Reference (à relire si besoin). Les deux premiers déclenchent une action ; les deux derniers ferment la boucle.
- Test immédiat ou créneau dédié : les « Adopt » passent dans la journée, sur un cas d’usage réel. Pas un exercice artificiel – un vrai projet en cours. Quinze à vingt minutes suffisent pour valider si le signal mérite d’être approfondi.
Ce protocole n’est pas universel. Si vous avez un usage moins intensif de l’IA, le seul critère qui compte est le dernier : avez-vous testé quelque chose cette semaine ?
Conseil un peu plus exigeant : utilisez au moins deux LLM, ou deux écosystèmes avec une approche 80/20. Les modèles évoluent vite, ont des logiques légèrement différentes, et vous développez une souplesse utile si les prix devaient doubler ou si un fournisseur devenait inaccessible.
Pour illustrer : je suis dans un écosystème Anthropic (Claude), mais j’utilise Google pour NotebookLM et un compte OpenRouter pour que mes API restent agnostiques de fournisseur. Comme mes usages sont distincts, ça ne crée pas de friction. J’injecte dans NotebookLM les ressources remarquables de la semaine ; ma routine génère un podcast de 20 minutes de synthèse que j’interroge ensuite. Si vous ne l’avez pas encore utilisé, NotebookLM est particulièrement adapté pour valoriser des sources hétérogènes (vidéos, textes, sites), jusqu’à 50 sources simultanées.
Une lecture complémentaire pour les managers : la distinction reconnaissance/compétence change la façon de penser la montée en compétences d’une équipe. La question pertinente n’est pas « mon équipe connaît-elle les techniques de prompting ? » mais « mon équipe teste-t-elle régulièrement des choses pertinentes ? ». Les compétences IA ont une durée de vie plus courte que les compétences métier classiques : les référentiels conçus pour des cycles de trois ans ne s’y appliquent pas.
Ce que j’en retiens
La montée en compétences sur le prompting ne ressemble pas à celle sur un framework logiciel : il n’existe pas de vraie documentation officielle exhaustive à parcourir du début à la fin. Elle ressemble davantage à l’apprentissage d’un instrument : les gammes (les techniques de base bien comprises) comptent plus que les morceaux complexes mal assimilés.
Dans mon usage, le changement le plus décisif n’est pas venu d’une technique nouvelle mais d’une meilleure compréhension de ce qui se passe dans un modèle quand on lui parle (fenêtre de contexte, flagornerie, instructions structurées, modèles « thinking »). C’est ce que la recherche confirme, et ce que les guides pratiques n’enseignent pas toujours. J’ai automatisé une partie de mon flux de veille pour classer directement les apports des différentes sources en Adopt/Adapt/Refence/Reject. J’ai bien conscience qu’il s’agit d’une approche avancée, et donc inadaptée à la plupart des usages (je vous laisse choisir ma géolocalisation entre Geekland et Normalland…).
Retenons un message principal : la veille est utile, mais elle ne remplace pas les vingt minutes de test qui suivent.
Exemple de prompt de « chaîne de vérification » :
Prompt principal :
Rédige un paragraphe de conclusion pour un article sur la veille IA
et le prompting, à destination de managers non-techniciens. La thèse
centrale est : la reconnaissance ne construit pas la compétence –
seule la pratique régulière le fait. Mentionne les travaux de
Schulhoff sur les 58 techniques de prompting, le concept de
connaissance tacite de Polanyi, et cite le résultat de Tang
et al. (2025) sur le few-shot dilemma.
Prompt de vérification enchaîné :
Relis le paragraphe que tu viens de produire et réponds à chacune
de ces questions par oui ou non, avec une justification courte :
La distinction reconnaissance/compétence est-elle présente et
clairement formulée ?
Schulhoff est-il cité avec précision (nombre de techniques, source) ?
La référence à Polanyi inclut-elle le concept de
« connaissance tacite » ?
Le résultat de Tang et al. (2025) est-il correctement attribué
et résumé sans erreur factuelle ?
Le registre est-il adapté à un manager non-technicien (absence
de jargon non défini) ?
Pour chaque « non » ou réponse mitigée, propose une correction
ciblée du passage concerné.Les opinions exprimées ici sont personnelles et n'engagent pas mon employeur.